
Quel est le rôle de l’apprentissage automatique dans la science des données ?

I write about fintech, data, and everything around it
Vous investissez dans le ML comme jamais auparavant et embauchez davantage de scientifiques des données et d’ingénieurs en apprentissage automatique. Cependant, il y a un manque de clarté sur le rôle de l’apprentissage automatique et sa place dans le cycle de vie d’un projet de science des données. Voici une tentative pour résoudre cette incertitude.
De nos jours, de nombreuses organisations et industries insistent sur l’utilisation des données pour améliorer leurs produits et services. Si nous parlons uniquement de science des données, il ne s’agit que d’analyse de données utilisant l’apprentissage automatique MLOps. L’apprentissage automatique et la science des données doivent aller de pair. Les ingénieurs doivent utiliser le ML et la science des données de manière proéminente pour prendre des décisions meilleures et plus appropriées.
Ainsi, cet article vous présentera l’apprentissage automatique et la science des données, le rôle du ML dans la science des données et comment ils sont différents les uns des autres tout en travaillant ensemble.
Dans cet article de blog, vous aurez un aperçu sur :
- Qu’est-ce que l’apprentissage automatique (ML) ?
- Pourquoi l’apprentissage automatique est-il important ?
- Qu’est-ce que la science des données ?
- Science des données vs apprentissage automatique
- Le rôle de l’apprentissage automatique dans la science des données
- Principales étapes de l’apprentissage automatique dans le cycle de vie de la science des données
Ok, commençons !
Qu’est-ce que l’apprentissage automatique (ML) ?
En termes simples, vous pouvez expliquer l’apprentissage automatique comme un type d’intelligence artificielle (IA) ou un sous-ensemble d’IA qui permet à toutes les applications logicielles ou applications d’être plus précises et précises pour trouver et prédire les résultats.
Les algorithmes d’apprentissage automatique utilisent des données historiques pour prédire de nouveaux résultats ou valeurs de sortie. Il existe différents cas d’utilisation de l’apprentissage automatique, tels que la détection des fraudes, la détection des menaces de logiciels malveillants, les moteurs de recommandation, le filtrage des spams, les soins de santé et bien d’autres.
Pourquoi l’apprentissage automatique est-il important ?
Pour toute entreprise, industrie et organisation qui gère les données comme un enregistrement principal ou un élément vital de celles-ci, et parallèlement à l’évolution, il y a également une augmentation de la demande et de l’importance. Cet aspect est la raison pour laquelle les ingénieurs de données et les data scientists ont besoin de l’apprentissage automatique.
Grâce à cette technologie, vous pouvez analyser une grande quantité de données et calculer les facteurs de risque en un rien de temps. L’apprentissage automatique a changé la façon dont l’ingénierie des données en termes de traitement, d’extraction et d’interprétation des données.
Qu’est-ce que la science des données ?
En utilisant des techniques et des outils modernes, ce domaine d’étude (la science des données) traite une énorme quantité de données pour trouver des modèles différents et invisibles, dériver des informations et prendre des décisions commerciales. La science des données, pour construire des modèles, utilise des algorithmes complexes d’apprentissage automatique.
La science des données combine plusieurs domaines tels que les méthodes scientifiques, les statistiques, l’analyse de données et l’intelligence artificielle pour extraire la valeur exacte des données. Les scientifiques de données et les ingénieurs de données combinent une gamme de compétences pour analyser et collecter des données à partir du Web et d’autres sources telles que les clients et les smartphones afin d’obtenir des informations exploitables.
Science des données vs apprentissage automatique
| SCIENCES DES DONNÉES | APPRENTISSAGE AUTOMATIQUE |
|---|---|
| C’est un domaine qui traite et extrait des données à partir de données semi-structurées et de données structurées. | C’est un domaine qui offre aux systèmes la capacité d’apprendre sans être programmés explicitement. |
| Il a besoin d’un univers d’analyse complet. | Il combine la science des machines et des données. |
| La branche s’occupe des données. | Les machines utilisent la science des données pour apprendre les données. |
| Les opérations de science des données comprennent la collecte, la manipulation, le nettoyage des données, etc. | Il existe trois types d’apprentissage automatique : non supervisé, supervisé et renforcé. |
| C’est un terme large qui s’occupe du traitement des données et se concentre sur les algorithmes. | ML se concentre uniquement sur les statistiques d’algorithme. |
| Exemple : Netflix utilisant la science des données est un exemple de cette technologie. Grâce aux données et aux analyses avancées obtenues grâce à l’application de la science des données, Netflix peut fournir aux utilisateurs des recommandations personnalisées sur les films et les émissions. Il peut également prédire la popularité du contenu original avec des bandes-annonces et des images miniatures. | Exemple : Facebook utilisant le machine learning est un exemple de cette technologie. Grâce à l’apprentissage automatique, Facebook peut produire le taux d’action estimé et le score de qualité de l’annonce qui est utilisé pour l’équation totale. Les fonctionnalités ML telles que la reconnaissance faciale, l’analyse textuelle, la publicité ciblée, la traduction linguistique et le fil d’actualités sont également utilisées dans de nombreux scénarios réels. |
Le rôle de l’apprentissage automatique dans la science des données
La science des données consiste à découvrir des résultats à partir de données brutes. Cela peut être fait en explorant les données à un niveau très granulaire et en comprenant les comportements et les tendances complexes. C’est là que l’apprentissage automatique entre en jeu.
Mais, avant d’analyser les données, vous devez comprendre clairement les exigences de l’entreprise pour appliquer l’apprentissage automatique.
Mais qu’est-ce que l’apprentissage automatique ?
En termes simples, la technologie d’apprentissage automatique permet d’analyser et d’automatiser de gros volumes de données et de faire des prédictions en temps réel sans impliquer les gens.
Nous utilisons des algorithmes d’apprentissage automatique en science des données lorsque nous voulons faire des estimations précises sur un ensemble de données donné, par exemple, si nous devons prédire si un patient a un cancer en fonction des résultats de ses analyses de sang. Nous pouvons le faire en fournissant à l’algorithme un grand nombre d’exemples : des patients qui ont ou n’ont pas eu de cancer et les résultats de laboratoire pour chaque patient. L’algorithme apprendra de ces exemples jusqu’à ce qu’il puisse prédire avec précision si un patient a un cancer en fonction de ses résultats de laboratoire.
Cela dit, le rôle de l’apprentissage automatique dans la science des données se déroule en 5 étapes :

Regardez cette vidéo de notre expert en science des données, Sanjeeya Velayutham, pour savoir exactement ce qu’est l’apprentissage automatique et comment il s’intègre dans le cadre plus large de la science des données.
Tout d’abord, comprenons la collecte de données.
La collecte de données est la première étape du processus d’apprentissage automatique. Selon le problème métier, l’apprentissage automatique permet de collecter et d’analyser des données structurées, non structurées et semi-structurées à partir de n’importe quelle base de données sur plusieurs systèmes. Il peut s’agir d’un fichier CSV, d’un pdf, d’un document, d’une image ou d’un formulaire manuscrit.
La deuxième étape est la préparation et le nettoyage des données.
La technologie d’apprentissage automatique aide à analyser les données et à préparer les fonctionnalités liées au problème métier dans la préparation des données. Les systèmes ML, lorsqu’ils sont clairement définis, comprennent les caractéristiques et les relations entre eux.
Notez que les fonctionnalités sont l’épine dorsale de l’apprentissage automatique et de tout projet de science des données.
Une fois la préparation des données terminée, nous devons nettoyer les données car les données dans le monde réel sont assez sales et corrompues par des incohérences, du bruit, des informations incomplètes et des valeurs manquantes.
Avec l’aide de l’apprentissage automatique, nous pouvons trouver les données manquantes et procéder à l’imputation des données, encoder les colonnes catégorielles, supprimer les valeurs aberrantes, les lignes en double et les valeurs nulles beaucoup plus rapidement de manière automatisée.
La prochaine étape est la formation du modèle.
La formation du modèle dépend à la fois de la qualité des données de formation et du choix de l’algorithme d’apprentissage automatique. Un algorithme ML est sélectionné en fonction des besoins de l’utilisateur final.
De plus, vous devez tenir compte de la complexité de l’algorithme du modèle, des performances, de l’interprétabilité, des besoins en ressources informatiques et de la vitesse pour une meilleure précision du modèle.
Une fois le bon algorithme d’apprentissage automatique sélectionné, l’ensemble de données de formation est divisé en deux parties pour la formation et les tests. Ceci est fait pour déterminer le biais et la variance du modèle ML.
À la suite de la formation sur le modèle, vous obtiendrez un modèle de travail qui pourra être davantage validé, testé et déployé.
Une fois la formation du modèle terminée, différentes métriques permettent d’évaluer votre modèle. N’oubliez pas que le choix d’une métrique dépend entièrement du type de modèle et du plan de mise en œuvre. Bien que le modèle ait été formé et évalué, cela ne signifie pas qu’il est prêt à résoudre les problèmes de votre entreprise. Tout modèle peut être affiné davantage pour une meilleure précision en ajustant davantage les paramètres.
L’étape finale et la plus cruciale d’un projet de science des données est la prédiction du modèle.
Chaque fois que nous discutons de la prédiction d’un modèle, il est essentiel de comprendre les erreurs de prédiction (biais et variance).
Acquérir une bonne compréhension de ces erreurs vous aiderait à construire des modèles précis et à éviter l’erreur de sur-ajustement et de sous-ajustement du modèle.
Vous pouvez réduire davantage les erreurs de prédiction en trouvant un bon équilibre entre le biais et la variance pour un projet de science des données réussi.
Éclipsant d’autres aspects de la science des données, l’apprentissage automatique (ML) et l’intelligence artificielle (IA) ont dominé l’industrie de nos jours de la manière suivante :
- L’apprentissage automatique analyse et examine automatiquement de gros volumes de données.
- Il automatise le processus d’analyse des données et fait des prédictions en temps réel sans aucune intervention humaine.
- Vous pouvez en outre créer et former le modèle de données pour effectuer des prédictions en temps réel. C’est à ce stade que vous utilisez des algorithmes d’apprentissage automatique dans le cycle de vie de la science des données.
Dans la section suivante, nous étudierons les principales étapes impliquées dans un flux de travail typique d’apprentissage automatique.
Principales étapes de l’apprentissage automatique dans le cycle de vie de la science des données
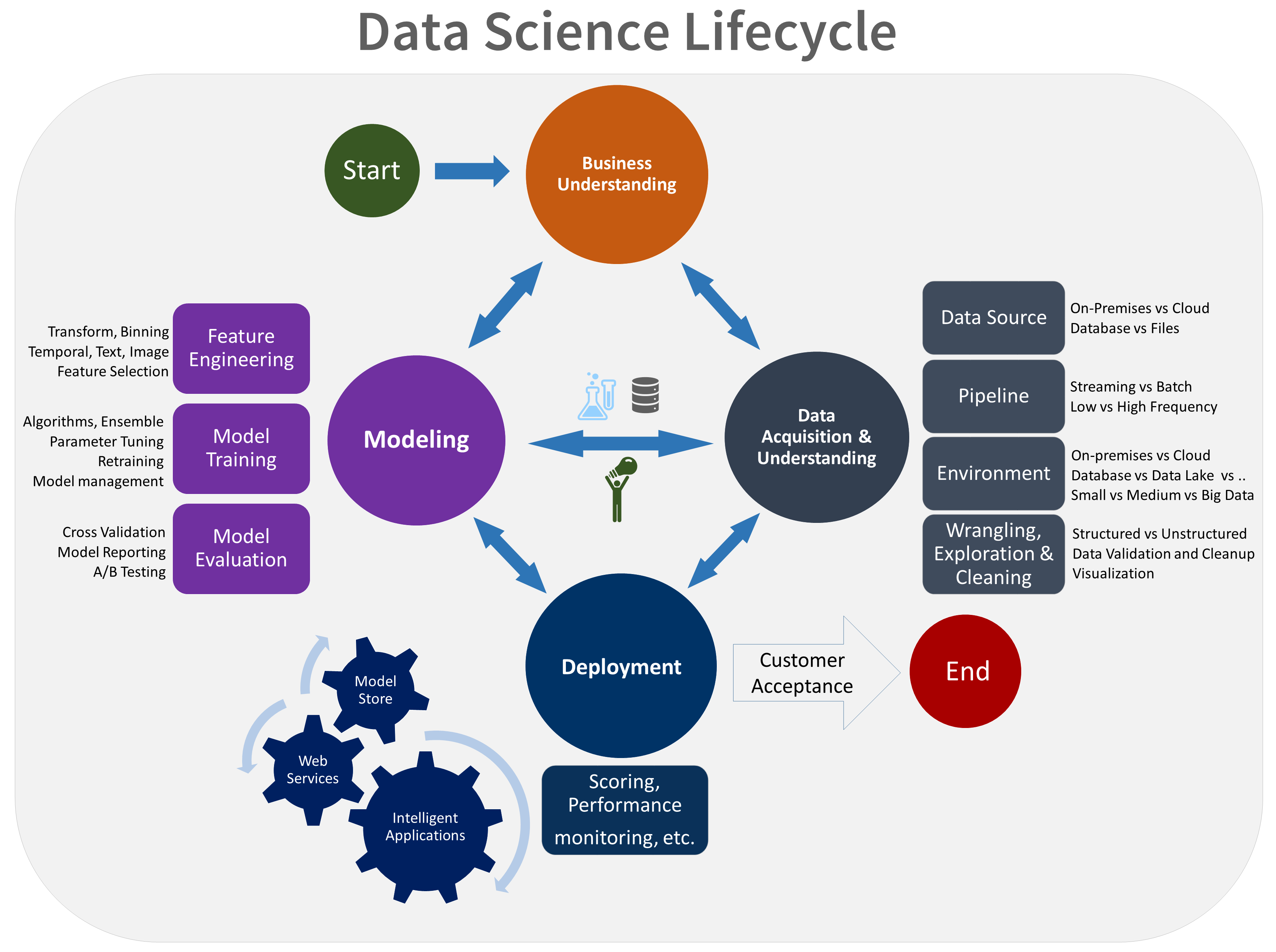
Principales étapes de l’apprentissage automatique dans le cycle de vie de la science des données
Source : Microsoft
Le diagramme ci-dessus est la représentation picturale de la façon dont vous pouvez entraîner le modèle de données et acquérir des données pour prendre des décisions commerciales. Apprenons à l’exécuter :
Obtenir des données → Préparer des données → Modèle d’entraînement → Tester des données → Améliorer
- Collecte de données: Il est connu pour être le fondement ou l’étape primaire. Il est essentiel de collecter des données pertinentes et fiables qui ont un impact sur les résultats.
- Préparation des données: La première étape globale de la préparation des données est le nettoyage des données. C’est une étape essentielle pour la préparation des données. Cette étape garantit que les données sont erronées et sans point de données corrompu.
- Formation modèle: Dans cette étape, l’apprentissage des données commence. Vous pouvez utiliser la formation pour prédire la valeur des données de sortie. Vous devez répéter cette formation de l’étape du modèle et le faire, encore et encore, pour améliorer et obtenir des prédictions plus précises.
- Test de données: Une fois que vous avez terminé les étapes ci-dessus, vous pouvez faire l’évaluation. L’évaluation garantit que l’ensemble de données que nous obtenons fonctionnera dans des applications réelles.
- Prédictions : Une fois que vous avez entraîné et évalué le modèle, cela ne signifie pas que l’ensemble de données est parfait et prêt à être déployé. Vous devez encore l’améliorer en le réglant. Cette étape est la dernière étape de l’apprentissage automatique. Ici la machine répond à chacune de vos questions par son apprentissage.
Conclusion
De nos jours, les organisations exploitent le potentiel des données pour améliorer leurs produits et services. La devise principale de cet article était d’expliquer comment la science des données et l’apprentissage automatique se complètent, l’apprentissage automatique facilitant la vie d’un scientifique des données.
Dans certains scénarios réels – moteurs de recommandation en ligne, reconnaissance vocale (dans Siri et Google Assistant), détection de la fraude dans toutes les transactions en ligne – la science des données et l’apprentissage automatique fonctionnent ensemble et fournissent des informations précieuses sur les données. Ainsi, il ne sera pas faux d’en déduire que l’apprentissage automatique peut analyser des données et extraire des informations précieuses.
Ainsi, l’apprentissage automatique deviendra l’une des technologies les plus recherchées dans un avenir proche. Il fera les applications les plus productives à l’avenir et s’imposera comme l’une des technologies les plus demandées en science des données.
Nous espérons que cet article vous plaira et que vous apprendrez comment l’apprentissage automatique fait partie intégrante de la science des données ! Réserver une prestation découverte avec nos architectes de données dès aujourd’hui et prenez une longueur d’avance sur la concurrence. Rendez-le simple et rendez-le rapide.
Lire la suite :
- Top 8 des tendances en Business Intelligence en 2022
- Qu’est-ce qu’une matrice de corrélation ? Comment l’utiliser pour prendre des décisions commerciales ?
- Qu’est-ce que la gouvernance des données ? Quelle est son importance ?
- Comment configurer le processus d’analyse des données pour les données d’entreprise ?