What is the Role of Machine Learning in Data Science?

I write about fintech, data, and everything around it
You are investing in ML like never before and hiring more data scientists and machine learning engineers. However, there is a lack of clarity on the role of machine learning and its place in the life cycle of a data science project. Here’s an attempt to resolve this uncertainty.
Nowadays, many organizations and industries stress using data to improve their products and services. If we talk about just data science, then it is only data analysis using MLOps machine learning. Both machine learning and data science have to go hand in hand. Engineers have to use ML and data science prominently to make better and more appropriate decisions.
So, this article will introduce you to machine learning and data science, the role of ML in data science, and how they are different from each other yet work together.
In this blog post, you will get an overview on:
- What is Machine Learning (ML)?
- Why is Machine Learning Important?
- What is Data Science?
- Data Science vs. Machine Learning
- The Role of Machine Learning in Data Science
- Major Steps of Machine Learning in Data Science Life Cycle
Ok, let’s get started!
What is Machine Learning (ML)?
In simple words, you can explain machine learning as a type of artificial intelligence (AI) or a subset of AI which allows any software applications or apps to be more precise and accurate for finding and predicting outcomes.
Machine learning algorithms use historical data to predict new outcomes or output values. There are different use cases for machine learning like fraud detection, malware threat detection, recommendation engines, spam filtering, healthcare, and many others.
Why is Machine Learning Important?
For any business, industry, and organization to run data as a primary record or lifeblood of it, and along with evolution, there is also a rise in demand and importance. This aspect is why data engineers and data scientists need machine learning.
With the help of this technology, you can analyze a large amount of data and calculate risk factors in no time. Machine Learning has changed the way of data engineering in terms of data handling, extraction, and interpretation.
What is Data Science?
Using modern techniques and tools, Data science deals with a tremendous amount of data to find different and unseen patterns, derive information, and make business decisions. Data science, to build models, uses complex machine learning algorithms.
Data science combines multiple fields such as scientific methods, statistics, data analysis, and artificial intelligence to extract the exact value from data. Data scientists and data engineers combine a range of skills to analyze and collect data from the web and other sources such as customers and smartphones to derive actionable insights.
Data Science vs. Machine Learning
| DATA SCIENCE | MACHINE LEARNING |
|---|---|
| It is a field that processes and extracts data from semi-structured data and structured data. | It is a field that offers systems the ability to learn without being programmed explicitly. |
| It needs an entire analytics universe. | It combines machine and data science. |
| The branch deals with data. | Machines utilize data science for learning data. |
| Data science operations include data gathering, manipulation, cleaning, etc. | There are three types of machine learning: unsupervised, supervised, and reinforcement. |
| It is a broad term that takes care of data processing and focuses on algorithms. | ML only focuses on algorithm statistics. |
| Example: Netflix using data science is an example of this technology.
With the advanced data and analytics obtained from applying data science, Netflix can provide users personalized recommendations on movies and shows. It can also predict the original content’s popularity with trailers and thumbnail images. |
Example: Facebook using machine learning is an example of this technology.
Using machine learning, Facebook can produce the estimated action rate and the ad quality score which is used for the total equation. ML features such as facial recognition, textual analysis, targeted advertising, language translation and news feed are also used in many real-case scenarios. |
The Role of Machine Learning in Data Science
Data science is all about uncovering findings from raw data. This can be done by exploring data at a very granular level and understanding the complex behaviors and trends. This is where machine learning comes into play.
But, before analyzing data, you need to understand the business requirements clearly to apply machine learning.
What is machine learning?
In simple terms, machine learning technology helps analyze and automate large chunks of data and make predictions in real-time without involving people.
We use machine learning algorithms in data science when we want to make accurate estimates about a given set of data—for instance, if we need to predict whether a patient has cancer-based on the results of their bloodwork. We can do this by feeding the algorithm a large set of examples: patients that did or didn’t have cancer and the lab results for each patient. The algorithm will learn from these examples until it can accurately predict whether a patient has cancer-based on their lab results.
That said, the role of machine learning in data science happens in 5 stages:

Watch this video from our data science expert, Sanjeeya Velayutham, to learn what exactly is machine learning and how it fits into the bigger picture of data science.
First, let’s understand data collection.
Data collection is the first step of the machine learning process. As per the business problem, machine learning helps collect and analyze structured, unstructured, and semi-structured data from any database across systems. It can be a CSV file, pdf, document, image, or handwritten form.
The second step is data preparation and cleansing.
Machine learning technology helps analyze the data and prepare features related to the business problem in data preparation. ML systems, when clearly defined, understand the features and relationships between each other.
Note that features are the backbone of machine learning and any data science project.
Once data preparation is complete, we need to cleanse the data because data in the real world is quite dirty and corrupted with inconsistencies, noise, incomplete information, and missing values.
With the help of machine learning, we can find out the missing data and do data imputation, encode the categorical columns, remove the outliers, duplicate rows, and null values much faster in an automated fashion.
The next step is model training.
Model training depends on both the quality of the training data and the choice of the machine learning algorithm. An ML algorithm is selected based on end-user needs.
Additionally, you need to consider the model algorithm complexity, performance, interpretability, computer resource requirements, and speed for better model accuracy.
Once the right machine learning algorithm is selected, the training data set is divided into two parts for training and testing. This is done to determine the bias and variance of the ML model.
As a result of model training, you will achieve a working model that can be further validated, tested, and deployed.
Once model training is completed, there are different metrics to evaluate your model. Remember, choosing a metric completely depends on the model type and implementation plan. Although the model has been trained and assessed, this does not mean it is ready to solve your business problems. Any model can be fine-tuned further for better accuracy by further tuning the parameters.
The final and most crucial stage of a data science project is model prediction.
Whenever we discuss model prediction, it’s vital to understand prediction errors (bias and variance).
Gaining a proper understanding of these errors would help you build accurate models and avoid the mistake of overfitting and underfitting the model.
You can further minimize the prediction errors by finding a good balance between bias and variance for a successful data science project.
Overshadowing other data science aspects, machine learning (ML) and artificial intelligence (AI) have dominated the industry nowadays in the following ways:
- Machine learning analyzes and examines large chunks of data automatically.
- It automates the data analysis process and makes predictions in real-time without any human involvement.
- You can further build and train the data model to make real-time predictions. This point is where you use machine learning algorithms in the data science lifecycle.
In the next section, we will study the main steps involved in a typical machine learning workflow.
Major Steps of Machine Learning in Data Science Life Cycle
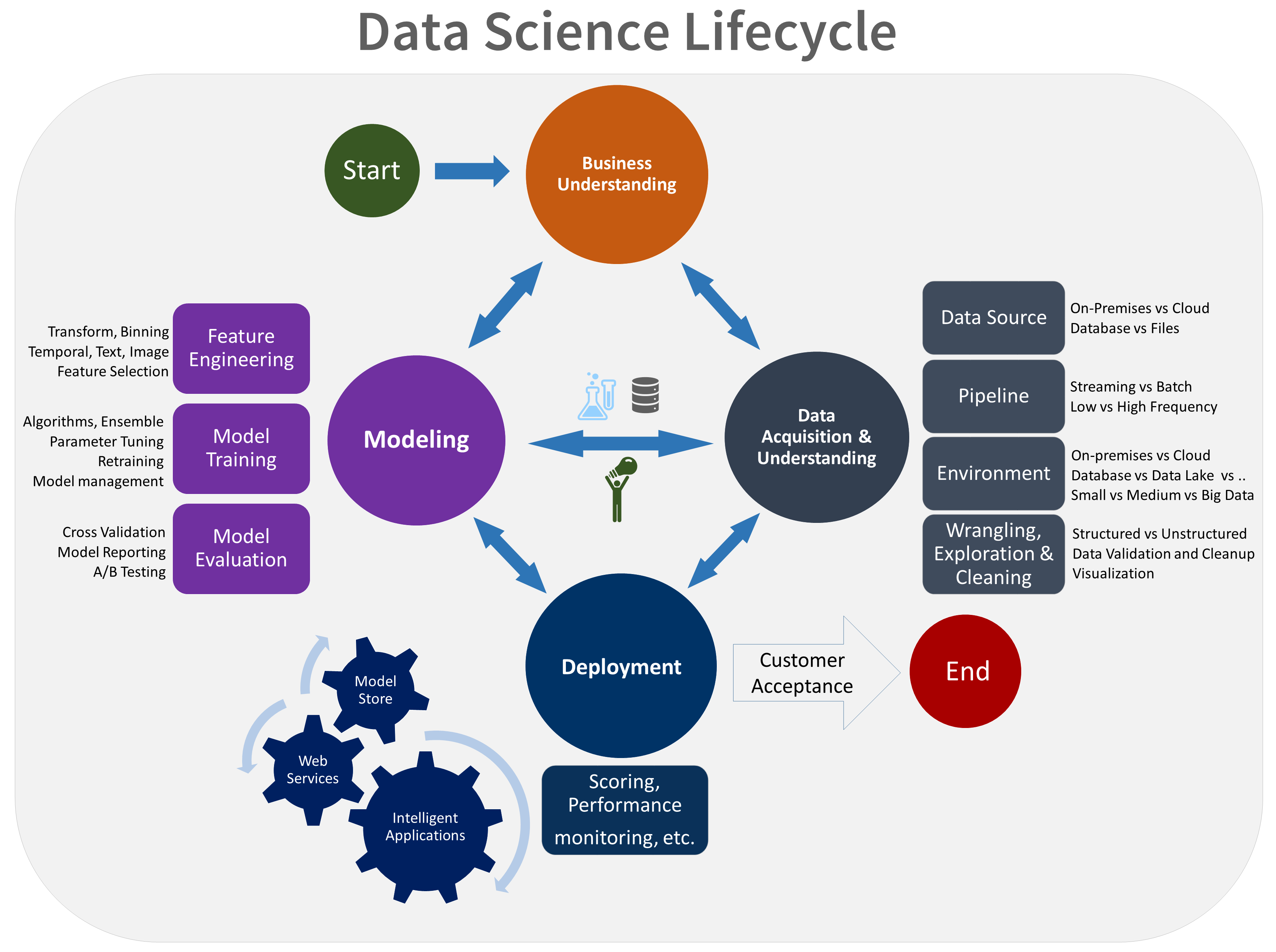
Major Steps of Machine Learning in Data Science Life Cycle
Source: Microsoft
The diagram above is the pictorial representation of how you can train the data model and acquire data in making business decisions. Let us learn how to execute it:
Getting Data → Preparing Data → Training Model → Testing Data → Improve
- Data Collection: It is known to be the foundation or primary step. It is essential to collect relevant and reliable data that impacts the outcomes.
- Data Preparation: The overall first step of data preparation is data cleaning. It is an essential step for preparing the data. This step ensures that data is erroneous and corrupt data point-free.
- Model Training: In this step, learning of data starts. You can use training to predict the output data value. You must repeat this training of the model step and do it, again and again, to improve and get more accurate predictions.
- Data Testing: Once you complete the above steps, you can do the evaluation. The evaluation makes sure that the data set that we get will perform in real-life applications.
- Predictions: Once you train and evaluate the model, it does not mean that the dataset is perfect and ready to be deployed. You have to further improve it by tuning. This stage is the final step of machine learning. Here the machine answers each of your questions by its learning.
Conclusion
Organizations these days have been embracing the potential of data for enhancing their products and services. This article’s main motto was to explain how Data Science and Machine Learning complement each other, with machine learning making the life of a Data Scientist easier.
In some real-life scenarios — online recommendation engines, speech recognition (in Siri and Google Assistant), detecting fraud in all the online transactions — data science and machine learning work together and give valuable data insights. Thus, it will not be wrong to infer that Machine Learning can analyze data and extract valuable insights.
Thus, machine learning will emerge as one of the most sought-after technologies in the near future. It will make the most productive applications in the future and prevail as one of the most demanded technologies in data science.
We hope you like this article and learn how machine learning is an intrinsic part of data science! Book a discovery service with our data architects today and get ahead of the competition. Make it simple & make it fast.
One Comment
Leave A Comment
Related Posts




















As someone deeply interested in the intersection of AI and sports, I was excited to see Intel’s AI platform making waves in athlete identification and development. This technology showcases the power of data-driven insights in predicting and enhancing athletic performance. In a recent article I wrote, I delve into how Intel’s AI could be the key to discovering the next Olympic champions. You can read more about the AI’s potential impact here: https://trendingcoolnews.com/intel-ai-technology-could-identify-the-next-olympic-superstar/ . I’m curious about what other applications you all see for AI in sports!