Wat is datamodellering (en waarom is het belangrijk)?

I write about fintech, data, and everything around it
In dit artikel‘de basisprincipes van datamodellering, waarom het belangrijk is om te gebruiken en de verschillende soorten datamodellen die je kunt maken voor uw bedrijf om u te onderscheiden van uw concurrenten.
Informatie is een waardevolle bron. Naarmate de tijd verstrijkt, worden er dagelijks meer en meer stukjes informatie gecreëerd. Zonder een robuuste data-engineeringstrategie kan uw bedrijf te maken krijgen met lange vertragingen, productiviteitsverlies, gefrustreerde klanten en beschadigde zakelijke relaties.
Goed gegevensbeheer en gegevensmodellering hebben een grote invloed op de groei van bedrijven, omdat ze bedrijven kunnen helpen informatie te verzamelen die hen een voorsprong geeft op hun concurrenten.
Toch blijft datamodellering een mysterie voor zakelijke belanghebbenden. Nu niet meer.
In deze blogpost krijg je een overzicht:
- Wat is gegevensmodellering?
- Waarom is gegevensmodellering belangrijk?
- Belang van gegevensmodellering
- Soorten gegevensmodellen
- Soorten gegevensmodellering
- 10 beste technieken voor geavanceerde datamodellering
- Hoe datamodellering implementeren in bedrijfsarchitectuur?
- Voorbeeld van datamodellering in de banksector
- Stappen in gegevensmodellering
- Hoe begin je met gegevensmodellering?
Oké, laten we beginnen!
Wat is gegevensmodellering?
Datamodellering is de belangrijkste stap in elk analytisch project. Datamodellen worden gebruikt om databases te maken, datawarehouses te vullen, gegevens te beheren voor analytische verwerking en applicaties te implementeren waarmee gebruikers op een zinvolle manier toegang kunnen krijgen tot informatie.
Gegevensmodellering is een proces dat je gebruikt om de gegevensstructuur van een database te definiëren. Met andere woorden, het is een techniek die je kunt gebruiken om een database vanaf nul te maken. Dit kan voor een eenvoudige database zijn waarin je informatie over klanten en producten opslaat, maar het kan ook voor iets veel gecompliceerders zijn, zoals een systeem dat wordt gebruikt om verkooptrends in een wereldwijd netwerk van winkels bij te houden.
Gegevensmodellering is het proces waarbij gegevens worden omgezet in informatie.
Alle informatie is nutteloos als deze niet wordt aangeleverd in een formaat dat kan worden geconsumeerd door zakelijke gebruikers. En datamodellering helpt bij het vertalen van de vereisten van zakelijke gebruikers naar een datamodel dat kan worden gebruikt om bedrijfsprocessen te ondersteunen en analyses te schalen.
Een goed datamodel moet al deze vragen kunnen beantwoorden:
- Wat zijn onze bedrijfsprocessen?
- Hoe structureren we onze bedrijfsinformatie?
- Welke soorten informatie gebruiken we binnen deze processen?
- Welke soorten informatie slaan we op?
- Waar komt het vandaan? Waar gaat het heen?
Bekijk deze video van onze Associate Consultant, Spoorthy Reddy, om te begrijpen hoe datamodellering wordt gebruikt om complexe bedrijfsproblemen op te lossen. En hoe het de datakwaliteit verbetert, bedrijfsrisico’s helpt identificeren en betere besluitvorming mogelijk maakt voor bedrijven (en zakelijke belanghebbenden). Bekijk de video en laat ons je mening of vragen weten in het commentaargedeelte van de video.
Waarom is datamodellering belangrijk (en wat zijn de voordelen)?
Datamodellering is een belangrijke fase van elk softwareproject omdat je zonder dat geen duidelijk beeld krijgt van hoe je database eruit moet zien en hoe je applicatie erop gebouwd wordt.
Datamodellering stelt je in staat om de mogelijke relaties tussen verschillende stukken informatie te identificeren, die bepalen welk type query’s tegen die gegevens kunnen worden uitgevoerd.
Datamodellering ondersteunt de bedrijfsarchitectuur (een datamodel voor een organisatie), die bedrijfsdoelen afstemt op technologiedoelen. Datamodellen ondersteunen ook andere elementen van Business Architectuur, zoals Data Governance, Business Intelligence en Applicatiearchitecturen, door te helpen bij het definiëren van hun vereisten tijdens het definiëren.
Als je niet van tevoren een gegevensmodel hebt, kun je eindigen met een systeem dat niet voldoet aan de behoeften van je gebruikers.
Belang van gegevensmodellering
Hier volgen enkele van de belangrijkste aspecten van gegevensmodellering:
- Organiseert gegevens: Gegevensmodellering structureert gegevens op een logische en georganiseerde manier, waardoor ze gemakkelijker te begrijpen en te beheren zijn.
- Verbetert de gegevenskwaliteit: Gegevensmodellering helpt bij het identificeren en corrigeren van inconsistenties en fouten in gegevens, wat leidt tot een betere gegevenskwaliteit.
- Garandeert gegevensintegriteit: Datamodellering dwingt beperkingen en relaties af, waardoor de integriteit van gegevens wordt gewaarborgd en afwijkingen in gegevens worden voorkomen.
- Ondersteunt besluitvorming: Goed ontworpen datamodellen bieden waardevolle inzichten en ondersteunen geïnformeerde besluitvormingsprocessen.
- Vergemakkelijkt databaseontwerp: Datamodellering is een cruciale stap in databaseontwerp en helpt bij het creëren van efficiënte en geoptimaliseerde databasestructuren.
- Vermindert redundantie: Gegevensmodellering minimaliseert gegevensredundantie door onnodige duplicatie van informatie te elimineren.
- Vereenvoudigt het ophalen van gegevens: Met een goed ontworpen gegevensmodel kunnen gegevens efficiënt en snel worden opgehaald, waardoor de systeemprestaties verbeteren.
- Verbetert applicatieontwikkeling: Gegevensmodellen dienen als blauwdruk voor de ontwikkeling van toepassingen, waardoor het eenvoudiger wordt om gegevens te integreren in softwareoplossingen.
- Maakt schaalbaarheid mogelijk: Een robuust datamodel ondersteunt toekomstige groei en schaalbaarheid en biedt ruimte voor extra gegevens zonder grote verstoringen.
- Bevordert standaardisatie: Gegevensmodellering bevordert standaardisatie en consistentie in de weergave van gegevens binnen de organisatie.
- Helpt data governance: Datamodellering vergemakkelijkt initiatieven op het gebied van datagovernance en zorgt voor naleving van regelgeving en beleid voor datamanagement.
- Ondersteunt gegevensanalyse: Gegevensmodellen bieden een gestructureerd kader voor gegevensanalyse en -rapportage, waardoor zinvolle inzichten mogelijk worden.
- Stimuleert samenwerking: Gegevensmodellering stimuleert samenwerking tussen bedrijfsanalisten, ontwikkelaars en belanghebbenden in het gegevensmodelleringsproces.
- Minimaliseert ontwikkelingsfouten: Door de gegevensvereisten vooraf te definiëren, vermindert datamodellering fouten tijdens de ontwikkelingsfase.
- Investering op lange termijn: Een goed onderhouden datamodel is een langetermijninvestering die waarde biedt gedurende de gehele levenscyclus van de data en applicaties.
Hier zijn slechts enkele van de vele redenen waarom het belangrijk is dat je applicaties een goed datamodel hebben:
Voordeel #1 van gegevensmodellering: applicaties van hogere kwaliteit
Het meest voor de hand liggende voordeel van datamodellering is dat het applicaties van hogere kwaliteit oplevert, die minder snel crashen en gemakkelijker te onderhouden zijn.
Als je geen datamodelleringstechnieken gebruikt om je applicaties te bouwen (en de kans is heel groot dat je dat niet doet), dan gebeurt het volgende:
- Je neemt ruwe gebruikersinvoer en stopt die in variabelen.
- Vervolgens manipuleer je die variabelen met code, waardoor nieuwe waarden ontstaan die vervolgens in andere variabelen worden geladen.
- Enzovoort, totdat je hopeloos genest bent met meerdere niveaus diep.
Het maakt niet uit of je organisatie groot of klein is. Als je applicatie is geschreven zonder enige structuur, is het resultaat spaghetti-code. En als je het ooit moet veranderen of nieuwe functies moet toevoegen, is al je code een warboel.
Voordeel #2: Lagere kosten en tijd voor applicatieontwikkeling
Datamodellering heeft een enorme invloed op de kosten en tijd die nodig zijn om een nieuwe applicatie te bouwen. Als je team geen gegevensmodel heeft, zul je tijd moeten besteden aan het verzamelen van vereisten van gebruikers en het handmatig coderen van de databasestructuur.
Als je wel een datamodel hebt, is het veel eenvoudiger om nieuwe tabellen en views toe te voegen, omdat je ze direct aan je datamodel kunt toevoegen. Als je tijdens het bouwen van een applicatie merkt dat je een tabel moet toevoegen of een bestaande tabel moet wijzigen, kun je deze gewoon toevoegen aan je datamodel en de bestaande applicatie bijwerken.
Als je geen datamodel hebt, dan moet je team zowel de database als de code bijwerken. Dit kan erg tijdrovend en duur zijn als je meerdere wijzigingen moet doorvoeren in de hele applicatie.
Voordeel 3 van gegevensmodellering: vroegtijdige detectie van dataproblemen en -fouten
In veel gevallen worden dataproblemen en -fouten pas ontdekt tijdens het proces. Een gebruiker kan bijvoorbeeld een aankoop doen en een foutmelding krijgen met “slechte gegevens”. In dit scenario waren de gegevens vanaf het begin slecht. Je kunt het testen in een lab of op een testserver, maar je ontdekt de fouten pas als het proces daadwerkelijk in productie draait.
Hoe eerder je een probleem met je gegevens ontdekt, hoe meer tijd je hebt om het te corrigeren voordat het negatieve gevolgen heeft voor je gebruikers.
Veel bedrijven gebruiken een Data Modeling-aanpak omdat het een nauwkeurig beeld geeft van de manier waarop uw gebruikers omgaan met uw bedrijf – tot in details zoals welke velden ze gebruiken en hoe vaak ze die gebruiken. Dit niveau van inzicht biedt cruciale informatie over waar problemen bestaan en hoe correcties het beste kunnen worden toegepast. Door regelmatig Data Model Audits uit te voeren, kun je ervoor zorgen dat je datamodel voortdurend geoptimaliseerd is voor je gebruikers en hun doelen.
Data Modellering Voordeel #4: Snellere prestaties van applicaties
Gegevensmodellering gaat niet alleen over geld besparen. Dat is natuurlijk belangrijk, maar de echte waarde van gegevensmodellering is dat het je applicatie sneller en efficiënter laat werken.
Gegevensmodellering is essentieel voor de prestaties van een applicatie omdat het een plan op hoog niveau biedt voor hoe de applicatie met gegevens moet omgaan. Dit betekent dat ontwikkelaars weten wat voor soort gegevens ze kunnen verwachten en hoe deze zullen worden gebruikt en waar in het geheugen elk stukje informatie zal worden opgeslagen. Dit betekent dat ze functies kunnen schrijven om snel en eenvoudig gegevens op te halen.
Dit is iets heel anders dan tabellen gebruiken om gegevens op een ongeorganiseerde manier op te slaan. Door ongestructureerde tabellen te gebruiken, zouden ontwikkelaars tijd moeten besteden aan het schrijven van complexe SQL-query’s die al dan niet opleveren wat ze zoeken. Door gestructureerde tabellen te gebruiken, weet de database-engine al hoe hij de informatie moet vinden – en hoeven ontwikkelaars zich geen zorgen te maken.
Het eindresultaat? Toepassingen zijn beter in staat om grote hoeveelheden gegevens te verwerken zonder te vertragen.
Voordeel #5: Betere documentatie voor onderhoud op lange termijn
Gegevensmodellen helpen om de bedrijfsprocessen en hun onderlinge relaties te definiëren. Als alle gegevens met betrekking tot een bedrijfsproces op één plek zijn gedefinieerd, wordt het eenvoudig om die processen te begrijpen en op lange termijn te onderhouden.
Datamodellering helpt ook bij het documenteren van de bedrijfsvereisten en het ontwerp van de applicatie. De vereisten en het ontwerp kunnen beter worden gecommuniceerd als er één bron voor is. Ook kunnen wijzigingen als gevolg van nieuwe vereisten, verbeteringen of bugfixes eenvoudig worden geïdentificeerd en geïmplementeerd.
Datamodellering is een belangrijk onderdeel van softwareontwikkeling; het vereist inspanning en expertise, maar de voordelen zijn de moeite waard.
Soorten gegevensmodellen
Een datamodel is een blauwdruk die de interne structuur van de informatie van een organisatie beschrijft. Datamodellen zorgen ervoor dat alle interne informatie consistent is en gemakkelijk toegankelijk is voor bevoegd personeel of belangrijke zakelijke belanghebbenden.
Een datamodel wordt gemaakt door te onderzoeken hoe de informatie op dit moment bestaat, de entiteiten binnen het systeem te identificeren en te bepalen waar ze in relatie tot elkaar staan. Het is vergelijkbaar met een organigram, maar in plaats van de lijnen van autoriteit te benadrukken, laat het zien hoe informatie is georganiseerd.
Gegevensmodelleurs gebruiken verschillende technieken om modellen te maken. Er zijn echter 3 hoofdtypen gegevensmodellering:
1. Conceptueel gegevensmodel
Conceptuele gegevensmodellen vormen de basis van elk gegevensmodel dat wordt gemaakt. Ze helpen je te begrijpen welke entiteiten er bestaan in je bedrijf en hoe ze zich tot elkaar verhouden. Conceptuele modellen bevatten geen details over de specifieke attributen die aan een entiteit zijn gekoppeld.
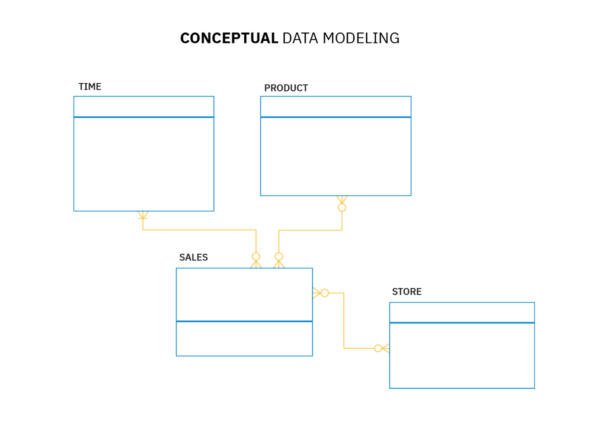
Een conceptueel model is een diagram dat beschrijft wat je bedrijf doet en hoe dingen samenwerken. Het is een hiërarchische weergave van entiteiten en hun relaties en wordt meestal gemaakt om belanghebbenden een breed overzicht van de database te geven. Tools voor gegevensmodellering kunnen u helpen om in een mum van tijd een conceptueel model voor uw database te maken.
Voordat je begint met het maken van een conceptueel gegevensmodel, moet je jezelf een aantal vragen stellen: Wat is het doel van je database? Wie gaat het gebruiken? Hoe wordt het gebruikt? Dit zal je helpen om te bepalen welke entiteiten in je database thuishoren en welke relaties er tussen hen bestaan.
2. Logisch gegevensmodel
Het Logical Data Model richt zich op de manier waarop gegevens worden opgeslagen in de systemen van een organisatie. Het logische model beschrijft hoe gegevens bewegen tussen de bron (bijvoorbeeld een persoon of een ander systeem) en de bestemming (bijvoorbeeld een database). Het gebruikt entiteiten, attributen, relaties, kardinaliteit en beperkingen om de entiteitenset voor elke tabel in een relationele database te beschrijven.
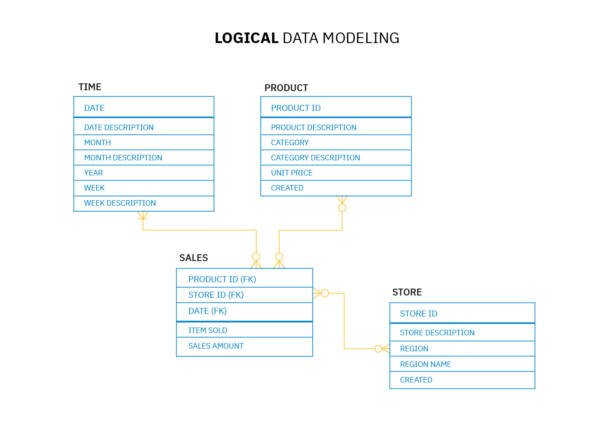
Het logische gegevensmodel vormt de basis voor het maken van fysieke gegevensmodellen. Deze kunnen worden gebruikt om tabellen te definiëren in relationele databases of objecten in objectgeoriënteerde talen zoals SQL, Java of C++.
3. Fysiek gegevensmodel
Fysieke gegevensmodellering is het proces van het definiëren van de structuur van een databaseschema om informatie op te slaan. Het fysieke model wordt meestal gemaakt door een databasebeheerder of systeemanalist. Het wordt gebruikt om tabellen, indexen en views te maken, die worden geïmplementeerd met behulp van Structured Query Language (SQL)-statements.
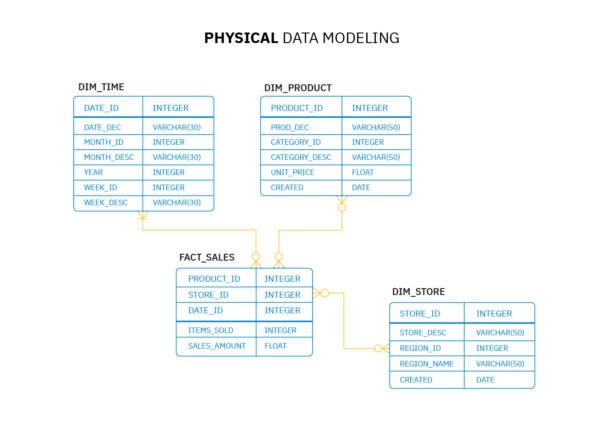
De eenvoudigste vorm van gegevensmodellering bestaat uit het maken van modellen die beschrijven hoe gegevens in tabellen moeten worden opgeslagen. Deze modellen worden vervolgens geïmplementeerd in een of meer databases. Een complexere vorm van datamodellering omvat het creëren van een logisch model dat beschrijft hoe gegevens worden benaderd en gemanipuleerd door eindgebruikers en applicaties die ze gebruiken.
Soorten gegevensmodellering
Gegevensmodellering is een diagram van de logische structuur van gegevens in een database. Gegevensmodellering kan mensen helpen gegevens beter te begrijpen en mensen die gegevens gebruiken om toekomstige uitkomsten te voorspellen.
Er zijn veel manieren om objecten uit de echte wereld te representeren in de software. De meest voorkomende modellen zijn hiërarchische, relationele, unified modeling language (UML), entiteit-relatie, object-georiënteerde en dimensionale datamodellen.
1. Hiërarchisch gegevensmodel
Een hiërarchisch gegevensmodel is een structuur voor het organiseren van gegevens in een boomachtige hiërarchie, ook wel ouder-kind relatie genoemd.
In een hiërarchisch gegevensmodel wordt elk record uniek geïdentificeerd door een sleutel, die dezelfde waarde heeft voor elk record op hetzelfde niveau in de hiërarchie.
Een typisch voorbeeld is een verkooporder: deze heeft veel verkoopitems, maar elk verkoopitem kan worden gekoppeld aan slechts één verkooporder. De verkooporder is de bovenliggende entiteit en het verkoopartikel is de onderliggende entiteit.
2. Relationeel gegevensmodel
Een relationeel model bevat knooppunten die aan elkaar gerelateerd zijn via links die relationele gegevens bevatten. Deze modellen worden vaak gebruikt om databases te maken waarmee informatie snel en gemakkelijk kan worden opgeslagen en opgehaald.
Het idee achter relationele databases is om alle soorten gegevens in één tabel op te slaan, zolang elke kolom een uniek stukje informatie over de entiteit vertegenwoordigt.
Een eenvoudig voorbeeld is een tabel voor het opslaan van informatie over mensen. De tabel zou kolommen hebben voor de voornaam, achternaam, burgerservicenummer, geboortedatum, enz.
3. ER-gegevensmodel (Entiteit-Relatie)
Het Entity-relationship (ER) model is een methode om je gegevens op een georganiseerde manier weer te geven. Het ER-model splitst de gegevens op in de volgende categorieën:
Entiteiten: De objecten, acties of concepten waarmee je werkt. Klanten, producten en verkoop zijn bijvoorbeeld allemaal entiteiten.
Relaties: De verbindingen tussen entiteiten. Dit kunnen één-op-één of één-op-veel relaties zijn.
Kenmerken: Gegevens die een entiteit of relatie beschrijven. De naam van een product is bijvoorbeeld een attribuut van dat product.
Om een solide ER-model te maken, moet je een duidelijk, gedetailleerd inzicht hebben in je bedrijfsprocessen en informatiebehoeften voor je gebruikers.
Het ER-diagram geeft een visuele weergave van hoe je gegevens aan elkaar gerelateerd zijn en welke processen ondersteund moeten worden door de database. Het laat ook zien hoe deze verschillende soorten gegevens aan elkaar gerelateerd zijn. Het is een grafische weergave van de onderliggende datamodelstructuur, waarmee je complexe informatie duidelijk en snel kunt communiceren.
4. Objectgeoriënteerd gegevensmodel
Een object-georiënteerd datamodel is een conceptueel datamodel dat objecten gebruikt om informatie te beschrijven en te definiëren. Dit in tegenstelling tot een entiteit-relatie model, dat informatie beschrijft als entiteiten verbonden door relaties.
Objecten zijn echte voorwerpen die bestaan uit verschillende attributen. Klanten hebben bijvoorbeeld namen, adressen, telefoonnummers, e-mailadressen, enz. Als de datamodelleur een entiteit-relatiemodel zou gebruiken om deze klanten te beschrijven, dan zouden deze attributen in aparte tabellen worden opgeslagen, met associaties tussen de tabellen gedefinieerd.
5. Dimensionaal gegevensmodel
Dimensionale datamodellen vormen de basis van business intelligence (BI) en online analytische verwerkingssystemen (OLAP). Deze modellen worden meestal geïmplementeerd voor datawarehouses die historische transactionele gegevens bevatten, maar kunnen ook worden toegepast op kleinere datasets.
Dimensionale datamodellen verwijzen vaak naar meerdere structuren die feitentabellen, dimensietabellen en opzoektabellen bevatten. Dimensionale modellering is de basis voor het creëren van enterprise data warehouses (EDW) en online transactieverwerkingssystemen (OLTP).
Het belangrijkste doel van een dimensioneel model is om gebruikers te helpen snel antwoorden te vinden op hun vragen over bedrijfsvoorspellingen, consumptietrends en andere gerelateerde vragen. Dimensionale modellering biedt een georganiseerde methode voor business intelligence rapportage. Het stelt gebruikers in staat om informatie te delen tussen verschillende afdelingen binnen een organisatie voor effectieve samenwerking en besluitvorming.
10 Geavanceerde technieken voor gegevensmodellering
Geavanceerde technieken voor datamodellering zijn geavanceerdere benaderingen die inspelen op complexe datascenario’s en gespecialiseerde vereisten. Deze technieken worden vaak gebruikt in grootschalige gegevensomgevingen, gegevensanalyse en geavanceerde gegevensbeheerscenario’s. Enkele van de geavanceerde technieken voor gegevensmodellering zijn:
1) Multidimensionale gegevensmodellering: Deze techniek wordt gebruikt in OLAP-systemen (Online Analytical Processing) om gegevens in meerdere dimensies te modelleren, zodat gebruikers gegevens vanuit verschillende perspectieven kunnen analyseren.
2) Temporele gegevensmodellering: Temporele gegevensmodellering houdt zich bezig met gegevens die in de loop van de tijd veranderen. Het omvat het vastleggen van historische gegevens, het beheren van tijdelijke relaties en het ondersteunen van tijdelijke queries om veranderingen over specifieke perioden te volgen.
3) Semigestructureerde gegevensmodellering: In scenario’s waar gegevens niet netjes in een rigide schema passen, worden semigestructureerde datamodelleringstechnieken gebruikt. Voorbeelden zijn JSON, XML en NoSQL databases.
4) Data vault modellering: Data vault modeling is een geavanceerde datawarehousingtechniek die is ontworpen voor schaalbaarheid, flexibiliteit en integratiegemak. Het richt zich op het bijhouden van historische gegevens en het integreren van gegevens uit meerdere bronnen.
5) Grafische gegevensmodellering: Graph Data Modeling wordt gebruikt voor het modelleren van gegevens met complexe relaties en netwerken. Het is geschikt voor toepassingen met sociale netwerken, aanbevelingssystemen en kennisgrafieken.
6) Big Data Modellering: Big Data Modeling houdt zich bezig met enorme hoeveelheden gegevens die worden gegenereerd door moderne toepassingen en systemen. Het bevat technieken voor het partitioneren van gegevens en optimalisatie om efficiënt met grote gegevens om te gaan.
7) Streaming datamodellering: Streaming data modeling wordt gebruikt voor het verwerken en analyseren van real-time datastromen uit bronnen zoals IoT-apparaten of sociale media. Het gaat om het verwerken van gegevens in beweging en het nemen van real-time beslissingen.
8) Modelontwerp voor machinaal leren: In de context van machinaal leren omvat gegevensmodellering het ontwerpen en trainen van modellen voor machinaal leren om voorspellingen en classificaties te doen op basis van gegevens.
9) Probabilistische gegevensmodellering: Bij probabilistische gegevensmodellering gaat het om het modelleren van onzekerheid en probabilistische relaties in gegevens, wat nuttig is in gebieden zoals Bayesiaanse statistiek en machinaal leren.
10) Conceptuele vermenging: Conceptuele vermenging is een cognitieve modelleringstechniek waarbij verschillende gegevensbronnen of concepten worden gecombineerd tot nieuwe ideeën of inzichten. Het wordt gebruikt bij het creatief oplossen van problemen en innovatie.
Hoe datamodellering implementeren in bedrijfsarchitectuur?
Het implementeren van gegevensmodellering in bedrijfsarchitectuur omvat een systematische aanpak voor het ontwerpen en implementeren van gegevensstructuren en -relaties in de hele organisatie. Hier volgen de stappen om gegevensmodellering effectief te implementeren in bedrijfsarchitectuur:
- Bedrijfsdoelstellingen definiëren: Begrijp de bedrijfsdoelstellingen en vereisten van de organisatie. Identificeer de belangrijkste gegevensbehoeften voor besluitvorming, rapportage, analyse en andere bedrijfsprocessen.
- Gegevensbronnen identificeren: Identificeer de gegevensbronnen binnen de organisatie, inclusief databases, applicaties, externe systemen en gegevensstromen.
- Gegevensinventarisatie: Maak een data-inventarisatie om de beschikbare data-assets in de organisatie te catalogiseren en te documenteren. Deze inventarisatie moet datatypes, gegevenseigenaren, gegevensformaten, gegevensstromen en gegevensgebruik bevatten.
- Samenwerking met belanghebbenden: Samenwerken met belanghebbenden uit verschillende bedrijfsonderdelen, IT, data governance en andere relevante teams om vereisten te verzamelen en ervoor te zorgen dat deze overeenkomen met de bedrijfsbehoeften.
- Gegevensbeheer: Beleid en procedures voor gegevensbeheer opstellen om de kwaliteit, beveiliging en naleving van gegevens te garanderen. Datamodellering moet voldoen aan deze richtlijnen voor data governance.
- Selecteer de aanpak voor datamodellering: Kies de juiste aanpak voor datamodellering voor de bedrijfsarchitectuur. Afhankelijk van de specifieke gebruikssituaties en vereisten kunnen dimensionale gegevensmodellering, ER-modellering of andere geavanceerde technieken voor gegevensmodellering geschikt zijn.
- Documentatie van gegevens: Documenteer de datamodellen en bijbehorende datadictionaries grondig zodat ze gemakkelijk te begrijpen zijn en in de toekomst geraadpleegd kunnen worden.
- Testen en valideren: Valideer de datamodellen en voer tests uit om de nauwkeurigheid, volledigheid en functionaliteit te garanderen.
- Voortdurende verbetering: Datamodellering in bedrijfsarchitectuur is een iteratief proces. Voortdurend datamodellen herzien en bijwerken naarmate de behoeften van de organisatie veranderen en er nieuwe databehoeften ontstaan.
Door deze stappen te volgen, kan een organisatie gegevensmodellering effectief implementeren in de bedrijfsarchitectuur, wat leidt tot beter gegevensbeheer, betere besluitvorming en meer efficiëntie in gegevensgerelateerde processen in de hele organisatie.
Voorbeeld van datamodellering in de banksector
Laten we eens kijken naar een vereenvoudigd voorbeeld van een Entity-Relationship Diagram (ERD) dat een gegevensmodel voor een bank voorstelt. Het datamodel zal drie hoofdentiteiten bevatten: Klant, Rekening en Transactie. Elke entiteit zal zijn attributen hebben en relaties tussen entiteiten zullen worden gelegd door ze te verbinden met lijnen.
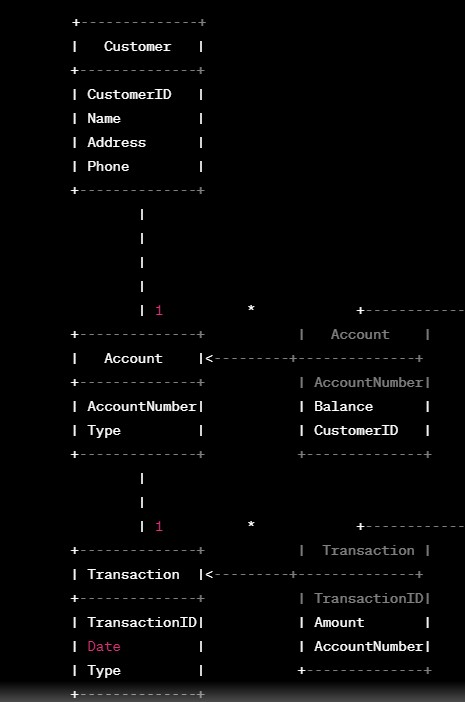
voorbeeld van gegevensmodellering
In het bovenstaande gegevensmodel:
- Klantentiteit: Vertegenwoordigt klanten van de bank. Het heeft attributen zoals Klant-ID, Naam, Adres en Telefoon.
- Rekeningentiteit: Vertegenwoordigt bankrekeningen aangehouden door klanten. Het heeft kenmerken zoals Rekeningnummer, Type (bijv. Sparen, Controleren) en Saldo.
- Transactie Entiteit: Vertegenwoordigt transacties op bankrekeningen. Het heeft kenmerken zoals transactie-ID, datum, type (bijv. storting, opname) en bedrag.
Relaties: De relaties worden weergegeven met lijnen die de entiteiten verbinden. De “1 op * (one-to-many)” relatie tussen Klant en Account betekent dat een klant meerdere accounts kan hebben. De “1 op * (one-to-many)” relatie tussen Rekening en Transactie geeft aan dat een rekening meerdere transacties kan hebben.
Stappen in gegevensmodellering
Gegevensmodellering kan ingewikkeld klinken, maar het is eigenlijk heel eenvoudig. Het is eigenlijk een proces van vragen stellen en antwoorden vinden.
Dit zijn de stappen die nodig zijn om gegevens te modelleren:
- Bekijk de zakelijke uitdaging
- De juiste gegevens uit het bedrijf halen
- Gegevens verzamelen en organiseren
- Een conceptueel model maken
- Het logische databaseontwerp bouwen
- Het fysieke databaseontwerp bouwen
- Breng belanghebbenden en hun eisen aan het datamodel in kaart
- Een kloofanalyse uitvoeren van vereisten vs. datasets
- Implementatie en documentatie van resultaten
- Datamodel meten en aanpassen aan veranderende eisen
Het doel van het datamodelleringsproces is om te definiëren en te documenteren hoe uw bedrijfsinformatie moet worden gemodelleerd binnen de enterprise data architectuur.
Zorg ervoor dat je elke stap doorloopt om fouten te voorkomen bij het implementeren van een Data Model. Hoe beter je gegevens en gegevensbewerkingen onderhoudt, hoe efficiënter het datamodel zal zijn.
Hoe begin je met gegevensmodellering?
Voor een succesvol datamodelleringsproject moet je eerst een datamodelleringsstrategie opstellen die je helpt bij het beslissen welke datamodellen je gaat bouwen.
Een goede data-analysestrategie omvat het verzamelen en documenteren van informatie over de data-architectuur van de onderneming, zodat alle belanghebbenden kunnen begrijpen wat de huidige stand van zaken is en wat de gewenste stand van zaken zou moeten zijn.
Download ons nieuwste eBook:
De strategiegids voor data-analyse
dat zich richt op het creëren van een effectieve data-analysestrategie die uw organisatie in staat stelt de inzichten te verwerven die nodig zijn om concurrerend te blijven in het huidige bedrijfsklimaat.
Als je nog steeds Denk je dat datamodellering ingewikkeld is? Wij helpen je om de resultaten te behalen die je wilt zonder alle frustratie. Boek een ontdekservice Neem vandaag nog contact op met onze data-architecten en wees de concurrentie een stap voor. Maak het eenvoudig en snel.